我是带着激动的心情写这篇经验的,因为困扰我很长时间的问题今天终于被解决:我成功提取了PDF文档中无法被复制的文本。首先,请大家仔细看下面两张来自不同的PDF文档的截图。
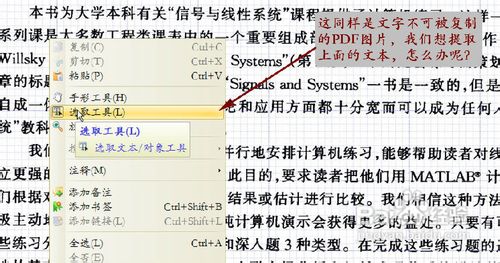
在第一张图所示的PDF文档中,文本文字都能够被自由复制,我们遇到的部分PDF文档就是这种类型。
然而,对第二张图所示的PDF文档,我们只能阅读它,无法复制其上的文本,这种文档有很多,今天,我们一起来看看提取这种文档的文本的方法。

工具/原料
计算机(带网络连接)
PDF-Xchange Viewer
Microsoft Word 2007(Word 2003也可以)
方法/步骤
1
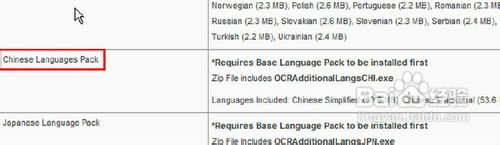
首先,我们为PDF-Xchange Viewer下载OCR中文识别模块。我们打开PDF-Xchange Viewer官方网站,找到“Chinese Language pack”选项,如图1。
2
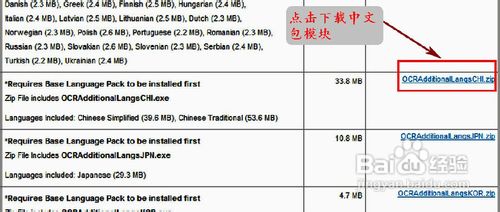
找到该项对应的“OCR AdditionalLanguagesCHI.ZIP”选项,左键单击它,进入下载页面。(如图2)
3
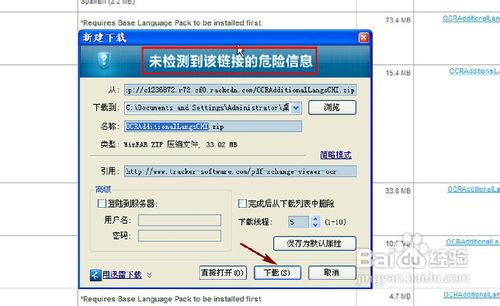
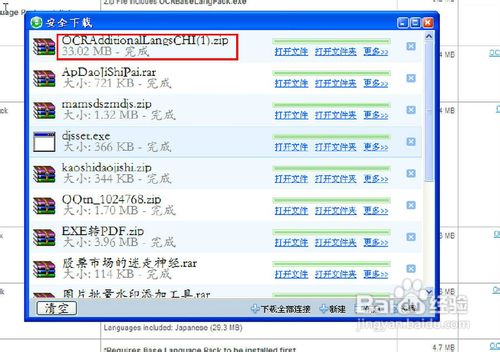
选择下载的目标位置,单击“下载”按钮,直至其下载完成,如图3、图4。
 END
END安装OCR中文识别模块。
1
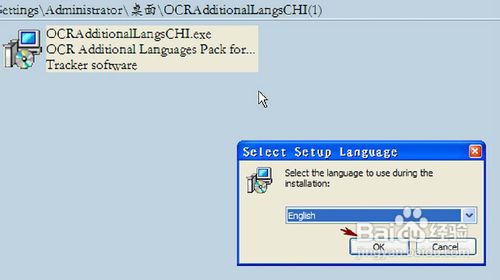
解压我们刚下载完成的“OCR AdditionalLanguagesCHI.ZIP”包,安装OCR中文识别模块,按照提示,单击“OK”按钮。(如图5)
2
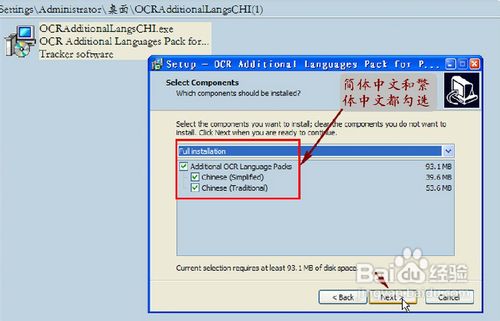
这一步,我们建议选择默认设置(即同时安装繁体中文和简体中文识别模块),单击“NEXT”按钮。(如图6)
3
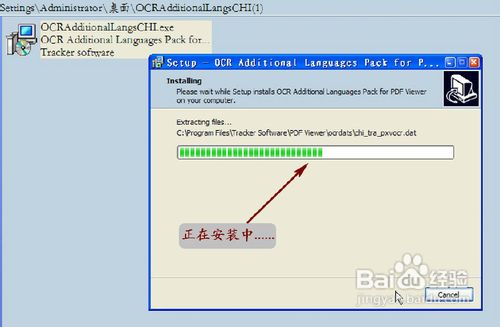
然后,我们耐心等待安装完成。(如图7)
 END
END应用OCR中文识别模块提取文本。
1
打开我们要识别并提取其文本的文档(用PDF-Xchange Viewer打开),当前这些文本只能看,不能被复制(如图8)。我们单击菜单栏的“文档”选项,选择“识别页面”选项。
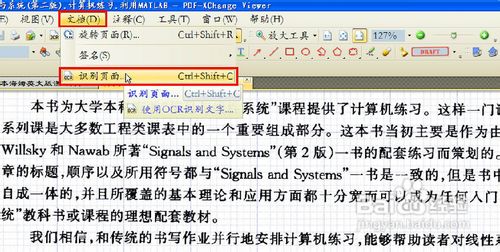
2
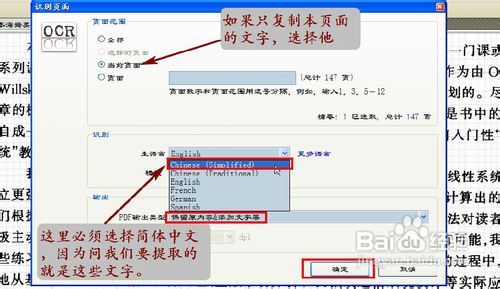
进入识别页面选项卡,如果我们仅需提取当前页面(仅此一页)的文本,勾选“当前页面”选项,在识别的主语言中,必须选择“Chinese(Simplied)”选项。(因为我们要提取的就是这些文字),然后单击“确定”按钮。(如图9)
3
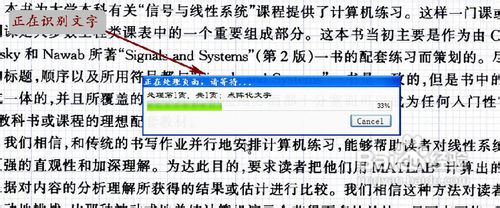
我们看到,OCR识别页面正在进行。(如图10)
4
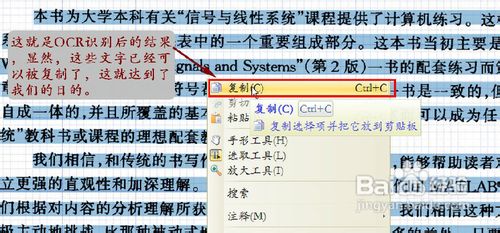
处理完成以后的页面如图11所示,我们惊喜地发现:这些原来不可被复制的文字已经可以被复制了!我们选取好想要复制的文本,单击右键,复制即可。
5
现在我们打开Microsoft Word 2007,粘贴刚才复制的文本。(如图12)
6
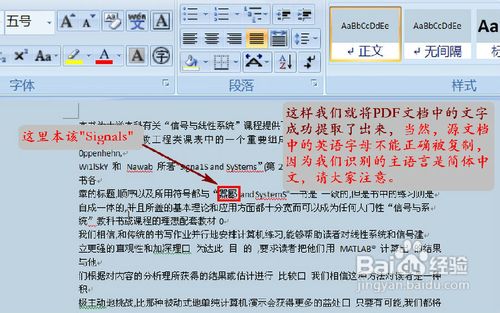
如图13,我们看到,这些文字已经被成功提取,值得注意的是:原文档中的非中文字符可能出现复制错误的情况(当然,这是极个别现象),如图中的某处错误,这里本该英文字符“Signals”。
 END
END注意事项
必须安装OCR中文识别模块,否则直接经OCR扫描后复制的文本是乱码,这点我深有体会。
当然,如果要复制的是英文字符,直接扫描后复制即可。
温馨提示:经验内容仅供参考,如果您需解决具体问题(尤其法律、医学等领域),建议您详细咨询相关领域专业人士。免责声明:本文转载来之互联网,不代表本网站的观点和立场。如果你觉得好欢迎分享此网址给你的朋友。转载请注明出处:https://www.i7q8.com/zhichang/7235.html
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 
